Cuando ves un vídeo generado por inteligencia artificial, es fácil quedarse en la superficie: “le das un texto y te devuelve un clip”. Funciona, sí, pero esa explicación es como decir que un coche “se mueve porque tiene ruedas”.
Lo interesante ocurre debajo.
Generar vídeo es uno de los problemas más complejos que está resolviendo la IA ahora mismo. No solo tiene que crear imágenes creíbles, sino hacer que todas encajen entre sí a lo largo del tiempo, sin romper la coherencia visual ni narrativa.
Vamos a desmontarlo paso a paso, pero con una idea clara en mente: esto no va de magia, va de cómo la IA aprende a construir realidad… frame a frame.
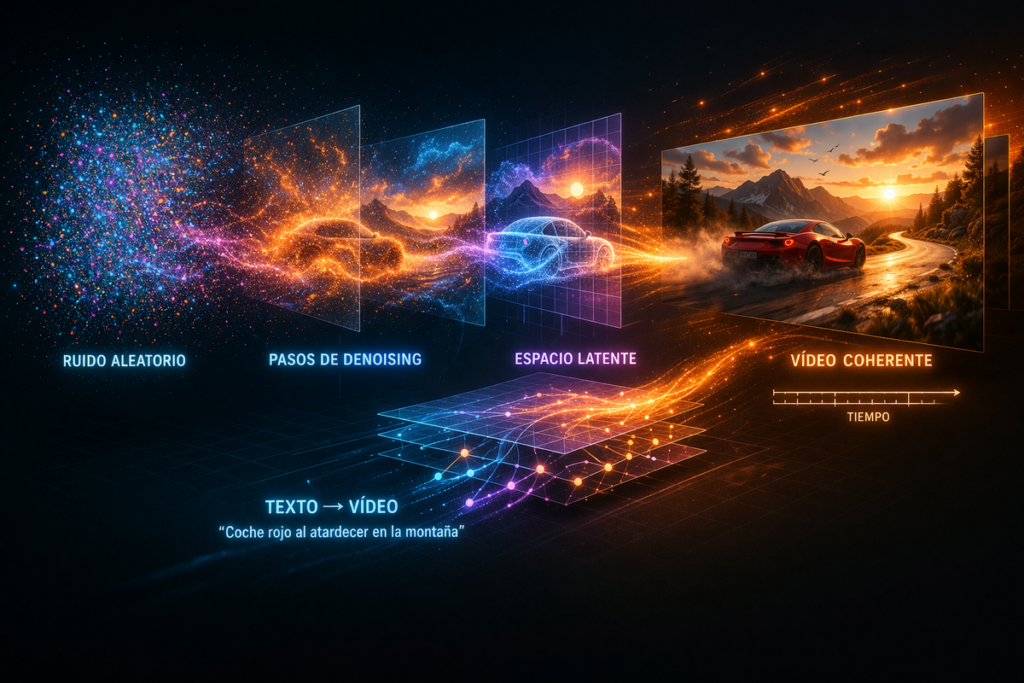
Todo empieza con ruido (literalmente)
Aunque suene extraño, muchos modelos de generación de imagen y vídeo empiezan desde algo completamente caótico: ruido aleatorio.
Imagina una pantalla llena de “puntos blancos”, como una televisión antigua sin señal. Ese es el punto de partida.
Durante el entrenamiento, el modelo aprende dos cosas:
Primero, cómo destruir una imagen añadiendo ruido progresivamente hasta que deja de tener sentido.
Y segundo, cómo revertir ese proceso: ir eliminando ruido poco a poco hasta recuperar una imagen coherente.
Cuando le pides un vídeo, el modelo hace esto:
empieza con ruido → lo va limpiando en múltiples pasos → aparece estructura → aparecen formas → aparece una escena.
No “dibuja” como lo haría un humano. Reconstruye patrones que ha aprendido.
Ejemplo sencillo
Piensa en una nube de puntos aleatorios.
En el paso 1 no ves nada.
En el paso 10 empiezas a ver contornos.
En el paso 30 ya parece una ciudad.
En el paso final… tienes una escena reconocible.
Ese proceso ocurre para cada frame… y ahí empieza el verdadero reto.
El problema real: no son imágenes, es tiempo
Si generar una imagen ya es complejo, generar vídeo añade una dimensión más: el tiempo.
Un vídeo no es solo una colección de imágenes. Es una secuencia donde cada frame depende del anterior.
Aquí es donde muchos fallan al imaginar cómo funciona la IA.
No genera “imagen 1, imagen 2, imagen 3” de forma independiente.
Genera algo más parecido a esto:
una escena que evoluciona de forma continua.
Ejemplo visual mental
Imagina que la IA genera esto:
- Frame 1: una persona mirando al frente
- Frame 2: la misma persona girando ligeramente
- Frame 3: continúa el movimiento
- Frame 4: termina el giro
Si cada frame se generara sin contexto, tendrías cuatro personas distintas que “se parecen”.
Pero el modelo aprende que:
esa persona debe ser la misma,
que su cara no cambia,
que la luz sigue siendo coherente,
y que el movimiento tiene continuidad.
Esto se llama coherencia temporal, y es uno de los grandes logros de los modelos actuales.
Qué “ve” realmente la IA: el espacio latente
Aquí viene una parte clave que suele generar confusión.
La IA no trabaja directamente con píxeles como tú ves una imagen. Sería demasiado costoso y poco eficiente.
En su lugar, convierte imágenes y vídeos en algo más abstracto: representaciones comprimidas llamadas espacio latente.
Piensa en ello como un idioma interno.
En lugar de almacenar “un árbol con hojas verdes”, el modelo trabaja con algo como:
- estructura vertical,
- textura orgánica,
- color dominante verde,
- contexto natural.
Todo eso se codifica en números.
Ejemplo práctico
Si tienes dos imágenes:
- un gato negro
- un gato blanco
en píxeles son completamente distintas.
Pero en el espacio latente están muy cerca: ambos son “gato”.
Esto permite que el modelo:
- entienda relaciones,
- generalice mejor,
- y genere contenido con coherencia.
En vídeo, estas representaciones no solo cambian en el espacio… cambian en el tiempo.
Cómo entra el texto en juego
Cuando escribes un prompt, ese texto no se traduce directamente a imágenes.
Primero se convierte en un vector (embedding), que es básicamente una representación numérica del significado.
Ese vector actúa como guía durante el proceso de eliminación de ruido.
Es como si le dijeras al modelo:
“todo lo que generes, tiene que encajar con esta idea”.
Ejemplo claro
Prompt:
“un coche rojo conduciendo por una carretera de montaña al amanecer”
El modelo no busca una escena exacta. Lo que hace es combinar patrones asociados a:
- “coche”
- “rojo”
- “carretera”
- “montaña”
- “amanecer”
Y durante cada paso de generación, ajusta el resultado para acercarse a esa combinación.
No sigue un guion. Sigue probabilidades.
Cómo se construye el movimiento
Aquí está una de las partes más interesantes.
Para generar movimiento, los modelos aprenden de millones de vídeos reales cómo cambian las cosas en el tiempo.
Aprenden cosas como:
- cómo se mueve una persona al caminar,
- cómo cambia la luz al atardecer,
- cómo fluye el agua,
- o cómo se desplaza una cámara.
Pero no memorizan vídeos concretos. Aprenden patrones de transición.
Ejemplo intuitivo
Si la IA ve muchos vídeos de olas, aprende que:
- el agua sube,
- rompe,
- y vuelve a caer.
Cuando genera vídeo, reproduce ese patrón, aunque la escena sea completamente nueva.
Es como aprender a bailar viendo miles de vídeos… sin copiar ninguno exactamente.
Arquitectura: varias piezas trabajando juntas
Los sistemas actuales combinan diferentes tecnologías que trabajan en paralelo.
Por un lado, los modelos de difusión generan el contenido visual.
Por otro, los transformers ayudan a entender el contexto del texto y las relaciones complejas.
Y además, hay mecanismos específicos para vídeo que gestionan la dimensión temporal.
Algunos modelos generan clips cortos y luego los extienden.
Otros trabajan directamente con secuencias completas.
Otros interpolan entre frames para suavizar el movimiento.
No hay una única forma de hacerlo. Es un campo que todavía está evolucionando muy rápido.
Dónde sigue fallando (y por qué)
A pesar de todo esto, hay cosas que siguen siendo difíciles.
La consistencia es uno de los mayores retos. Mantener un personaje idéntico durante varios segundos no es trivial. Pequeñas variaciones se acumulan y acaban siendo visibles.
El control también es limitado. Puedes guiar el resultado, pero no dirigirlo con precisión milimétrica. No puedes coreografiar una escena como lo harías en un rodaje real.
Y luego está la física. A veces todo parece correcto… hasta que algo se mueve de una forma que no encaja del todo.
Ese “algo raro” que notas sin saber explicar por qué.
La IA no genera vídeo como un artista dibujando una escena. Lo hace como un sistema que aprende cómo se comporta el mundo y lo reconstruye desde el caos.
Desde ruido hasta movimiento coherente, pasando por representaciones abstractas y guiado por lenguaje, todo el proceso es una combinación de matemáticas, datos y aproximaciones.
Lo sorprendente no es solo que funcione, sino que cada vez lo hace mejor.
Y eso abre una puerta interesante: no solo cambia cómo se hacen los vídeos… cambia quién puede hacerlos.
Porque cuando entiendes el proceso, te das cuenta de algo importante:
no estás viendo solo un vídeo generado.
Estás viendo una predicción extremadamente sofisticada de cómo debería verse la realidad.
Y eso, bien pensado, es casi más impresionante.